
Fuzzing Counter-Strike: Global Offensive maps files with AFL
RealWorldCTF 2018 had a really fun challenge called “P90 Rush B”, an allusion to a desparate tactic employed in the Valve game “Counter-Strike: Global Offensive”. It was about finding and exploiting a bug in the map file loader used by a CS:GO server. During the CTF, I exploited a stack buffer overflow that was later described well in a writeup by another team.

Since this bug also affected the official CS:GO Windows client, it was eligible for Valve’s bug bounty program, and was in fact just a minor variation of an older report, so I reported it quickly after the CTF and it was patched promptly.
I collected an encouraging payout and decided to spent a bit of time to
find similar issues in this component, and learn a bit about black-box fuzzing
in the process, which I have not had the opportunity to do in the past. This
article should serve as a record for myself and others of my experience with
AFL in QEMU mode and the approach I took to fuzzing BSP files. It helped find
and analyze 3 remotely reachable stack-based and 5 heap-based memory corruption
issues in csgo.exe in about 3 days.
I should mention that Valve did not consider my heap-based bugs (linear overflows and some semi-controlled out-of-bounds writes) worthy of fixes, without me providing them with a full exploit, which would be very hard due to ASLR. Neverless I think these bugs would be very useful as part of an exploit chain. So you can find yourselves real 0days if you decide to reproduce my research.
Please note that I am a noob when it comes to black-box fuzzing and willing to learn, so please call me out if some of my decisions were bad, or I missed some tooling that could have made my life much easier. I appreciate any kind of feedback on this project.
BSP file format & attack surface
The file format used for maps in CS:GO (and probably all Source engine games) is called BSP, short for binary space partition, which is a convenient representation of objects in n-dimensional space. The format supports a lot more than just 3D information however. BSP files are handled by both server and client, because both need a certain subset of the map information to perform their respective tasks. It is remote attack surface because the client will download unknown maps from the server on a server-initiated map change.
What’s interesting from a security research perspective is that the outermost
parsing code is shared between client and server, and mostly corresponds to
what we can find in a 2007 leak of the Source engine source
code. As far as I can tell, the code
base has not changed much since then, and almost no security bug fixes have
been applied to the BSP parser. The entry point of the parser is the function
CModelLoader::Map_LoadModel.
Fuzzing setup
TL;DR follow the instructions at https://github.com/niklasb/bspfuzz to replicate.
For simplicity, I decided to fuzz the Linux server binary rather than the actual client (which can also run on Linux). It seemed more natural to fuzz a CLI application than a full-blown 3D game. With this approach I would obviously not have been able to find any client-specific issues, but I was hoping for low-hanging fruit in the shared code. The shared parsing code is already quite complex, and I did not have high hopes of getting any kind of decent performance when covering even more of the map loading process. My goal was at least 100 executions/second per core. To install the dedicated server, you can follow the official instructions.
I consulted a YouTube tutorial
to create a very simple map in
Hammer and was
surprised to find it a whooping 300KB in size already. The large size is mostly
due to the fact that most of the contained model data is stored in uncompressed
form. So I wrote a dirty little
script
that strips out some of the unnecessary data, while keeping the file structure
intact. Specifically, it strips down the data contained in the largest
lumps
to ~5% of their original size. The result is a 16KB
file
which probably can’t be fully loaded in the client anymore, but is consumed
by Map_LoadModel without errors. This was my entire corpus for now.
This is how you would load this map in the server:
$ LD_LIBRARY_PATH=`pwd`/bin ./srcds_linux -game csgo -console -usercon \
+game_type 0 +game_mode 0 +mapgroup mg_active +map test \
-nominidumps -nobreakpad
It will load the map from the file csgo/maps/test.bsp. This takes about 15
seconds or more, so absolutely not an option to use it for fuzzing directly.
Instead I decided to write my own
wrapper around the
shared libraries used by the server binary, the most important of which (for my
purposes) are:
engine.so– Main Source engine code (includes BSP parser)dedicated.so– Dedicated server implementation (includes application entry point)libtier0.so– Probably related to Steam / application management
The wrapper does the following:
- Call into
DedicatedMain(like thesrcds_linuxbinary would) to start up the server. - Regain control after initialization is done, by patching
NET_CloseAllSocketsinengine.soso that it jumps to thestartpoint()function. - Call the
forkserver()function (this is where we will tell AFL to fork later). - Call into
CModelLoader::GetModelForNamewhich loads a map from a given file name. - Exit as fast as possible.
This requires a couple of patches to engine.so and libtier0.so, which
are applied by a Python
script. Both the
wrapper and the patching script need to be adapted for every new version of the
server, to incorporate changed offsets.
AFL
There are some simple changes I had to make in AFL itself:
- The input file has to end with
.bspin order to be parsed properly byGetModelForName. - I need to be able to specify a custom point where the fork server is
started. I introduced the environment variable
AFL_ENTRY_POINTfor this, which is parsed by the QEMU part of AFL. From the way QEMU does recompilation, it probably has to specify the instruction at the beginning of a basic block. - Increase the timeout multiplicator when waiting for the fork.
With those changes applied, running the fuzzer becomes as simple as
$ export AFL_ENTRY_POINT=$(nm bspfuzz |& grep forkserver | cut -d' ' -f1)
$ export AFL_INST_LIBS=1
$ afl-fuzz -m 2048 -Q -i fuzz/in -o fuzz/out -- ./bspfuzz @@
Multi-processing is recommended, and is the default if you use my wrapper script. Here is the state after 5 minutes of fuzzing on 8 cores:
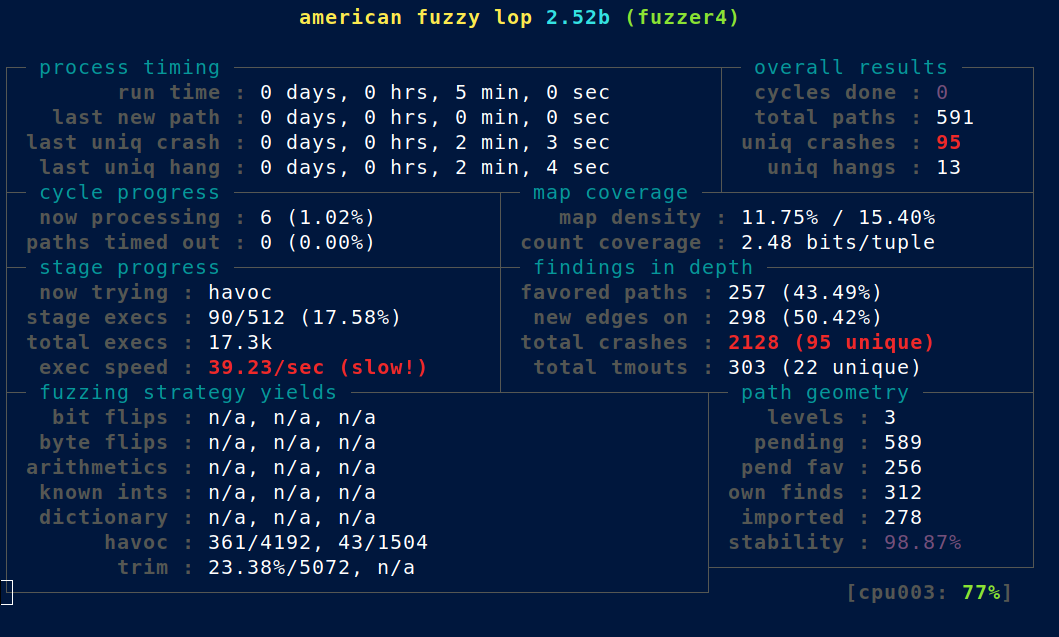
I get an average of ~50 executions/second/thread on my Ryzen 7 1800X. And after 1 week (the VM was suspended for another 2 weeks since then):
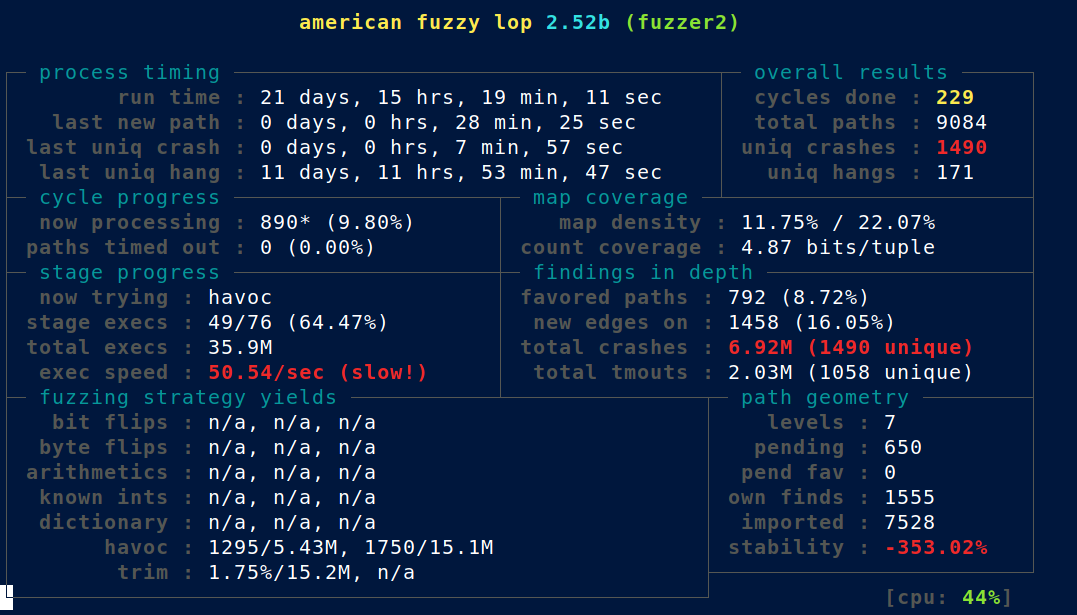
Triaging & Root cause analysis
Clearly we need some way of separating “good” bugs from uninteresting ones
(such as pure out-of-bounds reads) here. I went for a simple deduplication
based on the call stack and then ran each unique sample in Valgrind. Then
I grepped for Invalid write … I know, elaborate stuff.
$ sudo sysctl -w kernel.randomize_va_space=0
$ cd /path/to/bspfuzz/triage
$ ./triage.sh
$ ./valgrind.sh
$ egrep 'Invalid write' -A1 valgrind/* | egrep at | perl -n -e '/.*at (0x[^:]+)/ && print "$1\n";'
This will take a while. I am disabling ASLR here so that the crash locations are unique. I then started up valgrind once more manually to note down the base addresses of the libraries, and find the correct library and offset for each “invalid write” location.
Then for each of those locations, I manually reverse engineered the binary to find out if it corresponds to a function in the leaked source tree. In some cases it was new code, but the context provided by the available source code helped immensely with the reverse engineering. I gradually symbolized a lot of the BSP parser code, also using a collection of types gathered from the leaked header files.
For each PoC I verified that it also triggered on the Windows client. I didn’t find any interesting bugs that were present in the Linux server, but not the Windows client.
Takeaways
These are my personal lessons from this little project:
- AFL in QEMU mode is quite flexible for attacking a specific piece of code, if hacked slightly and with a wrapper binary.
- Input file size matters a lot. By going down from 300KB to 16KB I gained at least a factor of 5 in performance. Probably even smaller would be even better.
- Triaging is super important when sorting out code bases that haven’t been fuzzed before.
- Memory corruption on the heap is not a security problem :)
Example bug: Heap-buffer overflow in CVirtualTerrain::LevelInit
[This is just the report I sent to Valve. It’s a WONTFIX, i.e. will probably remain 0day as long as nobody provides them with an exploit.]
A heap buffer overflow occurs in CVirtualTerrain::LevelInit because the value
dphysdisp_t::numDisplacements variable can be larger than
g_DispCollTreeCount, and the assert that checks this case is not present in
the release build. An old version of the code can be found at
https://github.com/VSES/SourceEngine2007/blob/master/se2007/engine/cmodel_disp.cpp#L256:
void LevelInit( dphysdisp_t *pLump, int lumpSize )
{
if ( !pLump )
{
m_pDispHullData = NULL;
return;
}
int totalHullData = 0;
m_dispHullOffset.SetCount(g_DispCollTreeCount);
// [[ 1 ]]
Assert(pLump->numDisplacements==g_DispCollTreeCount);
// count the size of the lump
unsigned short *pDataSize = (unsigned short *)(pLump+1);
for ( int i = 0; i < pLump->numDisplacements; i++ )
{
if ( pDataSize[i] == (unsigned short)-1 )
{
m_dispHullOffset[i] = -1;
continue;
}
// [[ 2 ]]
m_dispHullOffset[i] = totalHullData;
totalHullData += pDataSize[i];
}
The assert at [[ 1 ]] is not present in the release build, so an overflow can
occur at [[ 2 ]]. What’s notable is that fact that the values
g_DispCollTreeCount and numDisplacements, as well as the contents of pDataSize
are taken verbatim from the BSP file, hence a lot of control can be exercised
by the attacker over the heap contents following the m_dispHullOffset buffer.
Thus, exploitability is very likely, especially since ASLR is not enabled for many
modules on Windows 7.
[I attached a BSP file with numDisplacements = 0xffff and g_DispCollTreeCount
= 2, which crashes csgo.exe reliably]